IDE
entorno de dasarrollo integrado
los IDE proveen un marco de trabajo amigable para mayoria de los lenguajesde programacion tales como ctt, python, java, c#delphi visual Basi ETC. en algunos lenguajes. un ID puede funcionar como un sistema en tiempo de ejecuccion en donde se permite utilizar el lenguaje de programacion.
es posible que un mismo IDE pueda funcionar con varios lenguajes de programacion. este es el caso de eclipse, a el que mediante plugins se le pueda añadir soporte de lenguajes adicionales.

 FRAGMEWORK
FRAGMEWORK
en el desarrollo de softwar e. un framewoork es una estrutura conseptual y tecnologica de soporte definida, normalmente con artefactos o modelos de software concretos, con base en la cual otro proyecto de software puede ser organizado y desarrollado. tipicamente y puede incluir soporte de programa .
representa una adquitetura de software que modela las relaciones generales de las entidades del dominio. proeve una estrutura y una metodologia de trabajo la cual extiende o utiliza las aplicaciones del dominio.
SDK
es generalmente un conjunto de herramientas de desarrollo que le permite a un programador crear aplicaciones para un sistema concreto, por ejemplo siertos paquetes de software , fragmewoorks, plataformas de had ware, computadores, video consolas, sistemas operativos, etc
 MOTOR DE BASE DE DATOS
MOTOR DE BASE DE DATOS
Este tema pertenece a la documentación de la versión preliminar y está sujeto a cambios en versiones futuras. Los temas en blanco se incluyen como marcadores de posición. NOTA: Con el fin de proporcionarle contenido adicional en distintos idiomas, Microsoft ofrece documentación localizada mediante métodos de traducción alternativos. Para esta versión preliminar, parte del contenido de esta documentación se ha traducido mediante el uso de estos métodos. Microsoft es consciente de que los documentos traducidos de esta forma no son siempre perfectos, por lo que es posible que este artículo contenga errores de vocabulario, sintaxis o gramática. La versión final de este contenido se traducirá por los métodos tradicionales y la calidad será igual que la de las versiones anteriores.]
GAPTCHA
Se trata de una prueba desafío-respuesta utilizada en computación para determinar cuándo el usuario es o no humano. El término se empezó a utilizar en el año
2000 por Luis von Ahn, Manuel Blum y Nicholas J. Hopper de la Carnegie Mellon University, y John Langford de IBM.
<><><><><><><><><>
Captcha es el
acrónimo de
Completely Automated Public Turing test to tell Computers and Humans
Apart (
Prueba de Turing pública y automática para diferenciar máquinas y humanos).

Este es un típico test para la secuencia "smwm" que dificulta el reconocimiento de la máquina distorsionando las letras y añadiendo un degradado de fondo
Se trata de una prueba desafío-respuesta utilizada
<><>
<><>
<><>
<><>
<>
SERBICIO WEB
un servidor web es un programa que esta diseñado para tranferir (hypertextos, paginas web, html hipertexto markup lenguaje) con elases, figuras, formularios botones y objectos incrustados como animaciones o productos de musica.
El programa implementa el
protocolo HTTP (
HyperText Transfer Protocol) que pertenece a la capa de aplicación del
modelo OSI. El término también se emplea para referirse al ordenador que ejecuta el programa.

Servidor web de la Wikimedia.
SISTEMAS DE INFORMACION
es un conjunto de elementos orientados altratamiento y administracion de datos e informacion, organizados y listos para su posterior uso, generados para cubrir una nesecidad (objectivo) dichos elementos formaran parte en alguna de esetas categorias:
- persopnas
- Datos.
- Actividades
Todos estos elementos interactúan entre sí para procesar los datos (incluyendo procesos manuales y automáticos) dando lugar a
información más elaborada y distribuyéndola de la manera más adecuada posible en una determinada organización en función de sus objetivos.
 CLASES DE SISTEMAS DE INFORMACION
Debido a que el principal uso que se da a los SI es el de optimizar el desarrollo de las actividades de una organización con el fin de ser más productivos y obtener ventajas competitivas, en primer termino, se puede clasificar a los sistemas de información en:
CLASES DE SISTEMAS DE INFORMACION
Debido a que el principal uso que se da a los SI es el de optimizar el desarrollo de las actividades de una organización con el fin de ser más productivos y obtener ventajas competitivas, en primer termino, se puede clasificar a los sistemas de información en:la planificacion de recursos empresariales es un termino deribado de la planificacion de recursos de mano facturas (mrp) y seguido de la planificacion de requerimiento de material (mrp) los sistemas erp tipicamente
manejan la producción, logística, distribución,
inventario, envíos, facturas
y contabilidad de la compañía. Sin embargo, la Planificación de Recursos Empresariales o el software ERP puede intervenir en el control de muchas actividades de
negocios como ventas, entregas, pagos, producción, administración de inventarios, calidad de administración y la administración de recursos humanos
ERP
La Planificación de Recursos Empresariales es un término derivado de la Planificación de Recursos de Manufactura (MRPII) y seguido de la Planificación de Requerimientos de Material (MRP). Los sistemas ERP típicamente manejan la producción, logística, distribución, inventario, envíos, facturas y contabilidad de la compañía. Sin embargo, la Planificación de Recursos Empresariales o el software ERP puede intervenir en el control de muchas actividades de negocios como ventas, entregas, pagos, producción, administración de inventarios, calidad de administración y la administración de recursos humanos.
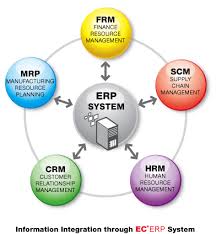 CRM
CRM
La administración basada en la relación con los clientes.
CRM, es un
modelo de gestión de toda la organización, basada en la orientación al cliente (u orientación al mercado según otros autores), el concepto más cercano es(según se usa en España) y tiene mucha relación con otros conceptos como:
Clienting, directo de etcétera.
- La administración de la relación con los clientes. CRM, es sinónimo de Servicio al cliente, o de Gestión de clien Con este significado CRM se refiere sólo a una parte de la gestión de la empresa.
- Software para la administración de la relación con los clientes. Sistemas informáticos de apoyo a la gestión de las relaciones con los clientes, a la venta y al marketing. Con este significado CRM se refiere al sistema que administra un Data warehouse (Almacén de Datos) con la información de la gestión de ventas y de los clientes de la empresa
BI
Se denomina
inteligencia empresarial,
inteligencia de negocios o
BI (del
inglés business intelligence) al conjunto de estrategias y herramientas enfocadas a la administración y creación de
conocimiento mediante el análisis de
datos existentes en una
organización o empresa.
Podemos diferenciar ademas un dato, de una información y un conocimiento, en esto se centra la inteligencia empresarial, ya que como sabemos el dato es algo vago, como por ejemplo "10 000", la información es algo mas preciso, como por ejemplo "Las ventas del mes de mayo fueron de 10 000" y el conocimiento se obtiene mediante el analisis de la informacion, y pues aqui interviene BI ya que, al obtener este conocimiento por ejemplo "El mes de mayo es el mas bajo en ventas", mediante esto podemos establecer estrategias, ya que al haber capturado la informacion de todas las areas en la empresa, hemos podido obtener conocimiento de el negocio, cuales son sus fortalezas y debilidades.
DATAWARE
En el contexto de la informática, un
almacén de datos (del
inglés data warehouse) es una colección de
datos orientada a un determinado ámbito (empresa, organización, etc.), integrado, no volátil y variable en el tiempo, que ayuda a la toma de decisiones en la entidad en la que se utiliza. Se trata, sobre todo, de un expediente completo de una organización, más allá de la información transaccional y operacional, almacenado en una base de datos diseñada para favorecer el análisis y la divulgación eficiente de datos (especialmente
OLAP, procesamiento analítico en línea). El almacenamiento de los datos no debe usarse con datos de uso actual. Los almacenes de datos contienen a menudo grandes cantidades de información que se subdividen a veces en unidades lógicas más pequeñas dependiendo del subsistema de la entidad del que procedan o para el que sean necesario.

Descripción de un Data Warehouse.
Un
formulario web dentro de una
página web permite al usuario introducir datos los cuales son enviados a un
servidor para ser procesados. Los formularios web se parecen a los
formularios de papel porque los internautas llenan dichos formularios usando casillas de selección,
botones de opcion, o campos de texto. Por ejemplo, los formularios web pueden ser usados para introducir datos de envío o datos de una tarjeta de crédito con el objetivo de solicitar un producto o bien ser utilizada para solicitar datos (p. ej., al buscar en un
Motor de búsqueda).
 URL
URL
El
esquema data: URI definido en las normas
IETF RFC 2397 en un
esquema URI que permite la inclusión de pequeños elementos de datos en línea, como si fueran referenciados hacia una fuente externa. Suelen ser mucho más simples que otros métodos de inclusión alternativos, como
MIME .De acuerdo a la denominación en el RFC, los
data: URI son, de hecho,
URLs.
Los URIs
data: están soportados actualmente por:
en su versión 7, no soporta los
data: URIs como fuentes HTML, por lo que algo como
about:<b>bold</b> en esas versiones es aproximadamente equivalente a
data:text/html,<b>bold</b> en navegadores que soportan l
 SQL
SQL
es un
lenguaje declarativo de acceso a relacionales que permite especificar diversos tipos de operaciones en éstas. Una de sus características es el manejo del
álgebra y el
cálculo relacional permitiendo efectuar
consultas con el fin de recuperar -de una forma sencilla-
información de interés de una base de datos, así como también hacer cambios sobre ella. Es un
lenguaje informático de cuarta generación (4GL).
 PLATAFORMA MULTIUSUARIO
PLATAFORMA MULTIUSUARIO
En contraposición a los sistemas
monousuario, que proveen servicio y procesamiento a un solo
usuario, en la categoría de multiusuario se encuentran todos los sistemas que cumplen simultáneamente las necesidades de dos o más usuarios, que comparten los mismos recursos. Actualmente este tipo de sistemas se emplean especialmente en redes, pero los primeros ejemplos de sistemas multiusuario fueron sistemas centralizados que se compartían a través del uso de múltiples dispositivos de interfaz humana (e.g. una unidad central y múltiples
pantallas y teclados).

MONOUSUARIO
Saltar a navegación, búsqueda
Un sistema operativo monousuario (de mono: 'uno'; y usuario) es un sistema operativo que sólo puede ser ocupado por un único usuario en un determinado tiempo. Ejemplo de sistemas monousuario son las versiones domésticas de Windows.Administra recursos de memoria procesos y dispositivos de las PC'SEs un sistema en el cual el tipo de usuario no está definido y, por lo tanto, los datos que tiene el sistema son accesibles para cualquiera que pueda conectarse.
- Sistemas Competitivos
- Sistemas Cooperativos
- Sistemas que modifican el estilo de operación del negocio
ERP
Desde un punto de vista empresarial
La primera clasificación se basa en la jerarquía de una organización y se llamó el modelo de la pirámideSegún la función a la que vayan destinados o el tipo de usuario final del mismo, los SI pueden clasificarse en:
Estos sistemas de información no

Evolución de los sistemas de información a lo largo del tiempo.
Un sistema distribuido se define como: una colección de computadoras separados físicamente y conectados entre sí por una
red de comunicaciones distribuida; cada máquina posee sus componentes de hardware y software que el usuario percibe como un solo sistema (no necesita saber qué cosas están en qué máquinas). El usuario accede a los recursos remotos (
RPC) de la misma manera en que accede a recursos locales, o un grupo de computadores que usan un software para conseguir un objetivo en común.
 SISTEMA CENTRALIZADO
SISTEMA CENTRALIZADO
El
Sistema Centralizado de Área de Tránsito Antofagasta, también conocido como SCAT-Antofagasta, es un sistema que permite monitorear, planificar y regular intersecciones de la red vial de
Antofagasta y sus alrededores mediante el uso de
hardware, software y cámaras. El centro de control se
encuentra ubicado en la ciudad de
Antofagasta,
Este sistema monitorea y regula las intersecciones de la red vial de la ciudad de
Antofagasta, gracias a la sincronización de
semáforos según el tráfico vehicular y peatonal. Lo que se logra es reducir los tiempos de viaje, al disminuir la espera en los semáforos de vehículos y personas; reducir la tasa de accidentes; y agilizar la detección y reparación de fallas de semáforos.
 SISTEMA OPERATIVO DE 32BITS Y64BITS
SISTEMA OPERATIVO DE 32BITS Y64BITS
En
arquitectura de computadoras, 64 bits es un adjetivo usado para describir
enteros, direcciones de memoria u otras unidades de datos que comprenden hasta 64
bits (8 octetos) de ancho, o para referirse a una arquitectura de
CPU y
ALU basadas en
registros, bus de direcciones o bus de datos de ese ancho.
Los
microprocesadores de 64 bits han existido en las
supercomputadoras desde 1960 y en servidores y estaciones de trabajo basadas en
RISC desde mediados de los
años 1990. En
2003 empezaron a ser introducidos masivamente en las
computadoras personales (previamente de
32 bits) con las arquitecturas
x86-64 y los procesadores
PowerPC G5.
PROTOCOLO DE COMUNICACIONES
En
informática, un
protocolo es un conjunto de reglas usadas por
computadoras para comunicarse unas con otras a través de una
red. Un protocolo es una convención o estándar que controla o permite la conexión, comunicación, y transferencia de datos entre dos puntos finales. En su forma más simple, un protocolo puede ser definido como las reglas que dominan la sintaxis, semántica y sincronización de la comunicación. Los protocolos pueden ser implementados por
hardware, software, o una combinación de ambos. A su más bajo nivel, un protocolo define el comportamiento de una conexión de hardware
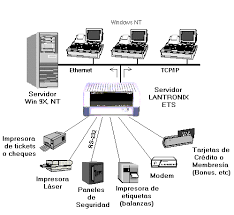 SWITCH
SWITCH
Un
switch KVM (Keyboard Video Mouse) es un dispositivo de conmutación que permite el control de
distintos equipos con tan sólo un monitor, un teclado y un ratón. Esta utilidad nos permite disponer en nuestro puesto de una única consola para manejar varios PC o servidores al mismo tiempo, conmutando de uno a otro según nuestras necesidades. Hay múltiples versiones que permiten la conmutación también de audio, micrófono y dispositivos periféricos mediante puertos USB. Existen también modelos con gestión de los PC o servidores a través de conexiones TCP/IP, por lo que podríamos manejar nuestros equipos a través de internet como si estuviéramos sentados frente a ellos. Dentro de las consolas con conexión TCP/IP existen para conexión serie (usada en equipos de comunicaciones y Unix) y de conexión gráfica
 INGENIERIA DEL SOFTWARE
INGENIERIA DEL SOFTWARE
La ingeniería es el conjunto de conocimientos y técnicas científicas aplicadas a la invención, perfeccionamiento y utilización de la técnica industrial en todos sus diversos aspectos incluyendo la resolución u optimización de problemas que afectan directamente a los seres humanos en su actividad cotidiana

Un
conmutador o
switch es un dispositivo digital de lógica de interconexión de
redes de computadores que opera en la capa 2 (nivel de enlace de datos) del modelo osi Su función es interconectar dos o más segmentos de red, de manera similar a los
puentes (bridges), pasando datos de un segmento a otro de acuerdo con la de destino de las
tramas en la red en la red.
METODOLOGÍAS DE DESARROLLO (CICLO DE VIDA CLASICO, INTERACTIVO,INCREMENTAL,CASCADA,RAD,CASE,XO,RUP, ETC.
EL Desarrollo con la burbuja de Mantenimiento de relieve. Los sistemas de ciclo de vida del desarrollo (SDLC), o del ciclo de vida de desarrollo de software en la ingeniería de sistemas e ingeniería de software, es el proceso de creación o alteración de los sistemas y los modelos y metodologías que la gente usa para desarrollar estos sistemas. El concepto general se refiere a la computadora o sistemas de información. En ingeniería de software el concepto de SDLC sostiene muchos tipos de metodologías de desarrollo de software. Estas metodologías constituyen el marco para la planificación y el control de la creación de una información system1: el proceso de desarrollo de software
PROGRAMACIÓN ESTRUCTURADA
En
computación, entrada/salida, también abreviado E/S o I/O (del original en inglés
input/output), es la colección de
interfaces que usan las distintas
unidades funcionale de un
sistema de procesamiento de información para comunicarse unas con otras, o las
señales (
información) enviadas a través de esas interfaces
 PROGRAMACIÓN ORIENTADA A OBJECTOS
PROGRAMACIÓN ORIENTADA A OBJECTOS
La programación orientada a objetos o POO (OOP según sus
siglas en
ingles es un paradigma de programacion
que usa
objetos y sus interacciones, para diseñar aplicaciones y programas
informaticos Está basado en varias técnicas, incluyendo
herencia, abstracción,
polimorfismo y
encapsulamiento. Su uso se popularizó a principios de la década de los años 1990. En la actualidad, existe variedad de lenguajes de programación que soportan la orientación a objetos
PATRONES DE DESARROLLO
Los patrones de diseño son la base para la búsqueda de soluciones a problemas comunes en el desarrollo de
software y otros ámbitos referentes al diseño de interacción o interfaces.
Un patrón de diseño es una solución a un problema de diseño. Para que una solución sea considerada un patrón debe poseer ciertas características. Una de ellas es que debe haber comprobado su efectividad resolviendo problemas similares en ocasiones anteriores. Otra es que debe ser reusable, lo que significa que es aplicable a diferentes problemas de diseño en distintas circunstancias.
 HTML
HTML
HTML, siglas de HyperText Markup Language (
Lenguaje de Marcado de Hipertexto), es el
lenguaje de marcado predominante para la elaboración de
páginas web. Es usado para describir la estructura y el contenido en forma de texto, así como para complementar el texto con objetos tales como imágenes. HTML se escribe en forma de "etiquetas", rodeadas por
corchetes angulares (<,>). HTML también puede describir, hasta un cierto punto, la apariencia de un documento, y puede incluir un
script (por ejemplo
Javascript), el cual puede afectar el comportamiento de
navegadores web y otros procesadores de HTML.
CSS
Las hojas de estilo en cascada (en
inglés Cascading Style Sheets), CSS es un lenguaje usado para definir la presentación de un documento estructurado escrito en
html o
xml (y por extensión en
XHTML). El
w3c (World Wide Web Consortium) es el encargado de formular la especificación de las
hojas de estilo
que servirán de estándar para los
agentes de usuario o
navegadores
 CONTROL DE VERSIONES
CONTROL DE VERSIONES
El control de versiones se realiza principalmente en la industria informática para controlar las distintas versiones del
codigo fuente. Sin embargo, los mismos conceptos son aplicables a otros ámbitos como documentos, imágenes, sitios web, etcétera
 LINUX
LINUX
A pesar de que
liux (nucleo) es, en sentido estricto, el sistema operativo parte fundamental de la interacción entre el núcleo y el usuario (o los programas de aplicación) se maneja usualmente con las herramientas del proyecto GNU o de otros proyectos como Sin embargo, una parte significativa de la comunidad, así como muchos medios generales y especializados, prefieren utilizar el término
Linux
para referirse a la unión de ambos proyect
 KERNEL
KERNEL
En
matemática una aplicación lineal (también llamada función lineal, transformación lineal u operador lineal) es una aplicación entre dos espacios vectoriales, que preserva las operaciones de suma de vectores y producto por un escalar. El término función lineal se usa también en análisis matemático y en geometría para designar una recta, un plano, o en general una variedad lineal
 DEMONIO
DEMONIO
es un tipo especial de
proceso informático que se ejecuta en segundo plano en vez de ser controlado directamente por el usuario (es un proceso no interactivo). Este tipo de programas se ejecutan de forma continua (infinita), vale decir, que aunque se intente cerrar o el proceso, este continuará en ejecución o se reiniciará automáticamente. Todo esto sin intervención de terceros y sin dependencia
Por ejemplo, una máquina que alberga un
servidor web utilizará un
demonio httpd (HTTP Daemon) para ofrecer el servicio y que los visitantes a dicha web puedan acceder. Otro ejemplo son los demonios "cronológicos" como cron, que realizan tareas programadas como mantenimiento del sistema en segundo plano.
 DISTRO DE LINUX
DISTRO DE LINUX
es una
distribución de software basada en el
núcleo Linux que incluye determinados
paquetes de software para satisfacer las necesidades de un grupo específico de usuarios, dando así origen a ediciones domésticas, empresariales y para servidores. Por lo general están compuestas, total o mayoritariamente, de
software libre, aunque a menudo incorporan aplicaciones o controladores
propietarios.
 NOMBRE DE DISTRIBUCIONES
NOMBRE DE DISTRIBUCIONES
 GNU
GNU
es un
acrónimo recursivo que significa
GNU No es Unix (
GNU is No es un
Sistema Operativo no libre muy popular, porque está basado en una arquitectura que ha demostrado ser técnicamente estable
t Unix).
 GPL
GPL
La
Licencia Pública General de GNU o más conocida por su nombre en
inglés GNU General Public License o simplemente sus siglas del inglés GNU GPL, es una licencia creada por la Free Software Foundation en 1989 (la primera versión), y está orientada principalmente a proteger la libre distribución, modificación y uso de software. Su propósito es declarar que el software cubierto por esta licencia es software libre y protegerlo de intentos de apropiación que restrinjan esas libertades a los usuarios.
 CONSOLA
Las CLI pueden emplearse interactívamente, escribiendo instrucciones en alguna especie de entrada de texto, o pueden utilizarse de una forma mucho más automatizada (batch), leyendo comandos desde un archivo de scripts.
Por ejemplo, las CLI son parte fundamental de los Shells o Emuladores de Terminal. Aparecen en todos los desktops (Gnome, KDE, Windows) como un método para ejecutar aplicaciones rápidamente. Aparecen como interfaz de lenguajes interpretados tales como Java, Python, Ruby o Perl. También se utilizan en aplicaciones cliente-servidor, en DBs (Postgres, MySQL, Oracle), en clientes FTP, etc. Las CLI son un elemento fundamental de aplicaciones de ingeniería tan importantes como Matlab y Autocad
CONSOLA
Las CLI pueden emplearse interactívamente, escribiendo instrucciones en alguna especie de entrada de texto, o pueden utilizarse de una forma mucho más automatizada (batch), leyendo comandos desde un archivo de scripts.
Por ejemplo, las CLI son parte fundamental de los Shells o Emuladores de Terminal. Aparecen en todos los desktops (Gnome, KDE, Windows) como un método para ejecutar aplicaciones rápidamente. Aparecen como interfaz de lenguajes interpretados tales como Java, Python, Ruby o Perl. También se utilizan en aplicaciones cliente-servidor, en DBs (Postgres, MySQL, Oracle), en clientes FTP, etc. Las CLI son un elemento fundamental de aplicaciones de ingeniería tan importantes como Matlab y Autocad.
 SAMBA
SAMBA
es una implementación libre del protocolo de archivos compartidos de Microsoft Windows (antiguamente llamado SMB, renombrado recientemente a CIFS) para sistemas de tipo UNIX. De esta forma, es posible que ordenadores con GNU/Linux, Mac OS X o Unix en general se vean como servidores o actúen como clientes en redes de Windows. Samba también permite validar usuarios haciendo de Controlador Principal de Dominio (PDC), como miembro de dominio e incluso como un dominio Active Directory para redes basadas en Windows; aparte de ser capaz de servir colas de impresión, directorios compartidos y autentificar con su propio archivo de usuarios.
 ESTRUTURA DE DIRECTORIOS Y PARA QUE SIRBEN
EJEMPLO
.
En sistemas de muchos usuarios se pueden tener cientos o miles de archivos. Para organizar y proteger todos estos archivos, en los sistemas UNIX, los archivos se organizan en directorios que a la vez pueden contener además de archivos otros directorios subdirectorios.
NOMBRE DE ADMINISTRADOR DE ARCHIBO
ESTRUTURA DE DIRECTORIOS Y PARA QUE SIRBEN
EJEMPLO
.
En sistemas de muchos usuarios se pueden tener cientos o miles de archivos. Para organizar y proteger todos estos archivos, en los sistemas UNIX, los archivos se organizan en directorios que a la vez pueden contener además de archivos otros directorios subdirectorios.
NOMBRE DE ADMINISTRADOR DE ARCHIBO es una
aplicación informática que provee acceso a archivos y facilita el realizar operaciones con ellos, como copiar, mover o eliminar archivos donde el usuario lo quiera ubicar.

FAT32,NTF,EXT
son tipos de sistemas de archivos
 UNIDAD PRIMARIA, SECUNDARIA, LOGICA
UNIDAD PRIMARIA, SECUNDARIA, LOGICA
es el nombre genérico que recibe cada división presente en una sola
unidad física de almacenamiento de datos. Toda partición tiene su propio
sistema de archivos (formato); generalmente, casi cualquier sistema operativo interpreta, utiliza y manipula cada partición como un disco físico independiente, a pesar de que dichas particiones estén en un solo disco físico
A algún tipo de partición se le da formato mediante algún
sistema de archivos como FAT, NTFS, ext4 ,ext3, ext2, FAT32, ReiserFS, Reiser4 u otro. En Windows, las particiones reconocidas son identificadas con una letra seguida por un signo de doble punto (p.e C:\ en Microsoft Windows) hasta cuatro particiones primarias; prácticamente todo tipo de discos magnéticos y memorias flash (como pendrives) pueden particionarse.
 UBUNTO 10.10
UBUNTO 10.10
es un sistema operativo linux basada en debian GNU/LINUX que proporciona un sistema operativo actualizado y estable para el usuario medio, con un fuerte enfoque y la facilidad de uso y de instalacion del sistema. al igual que otra distrubucion se compone multiples paquetes de software normalmente distribuidos bajo una licencia libre o de codigo abierto.
 FORMAS DE ISTALACION
por el gestor de archivos sinaptic, por el centro de software, por consola, instalación tipo windows para archivos .dev, por "ejecutar una aplicacion" presionando alt+ f2 y POR CONSOLA
FORMAS DE ISTALACION
por el gestor de archivos sinaptic, por el centro de software, por consola, instalación tipo windows para archivos .dev, por "ejecutar una aplicacion" presionando alt+ f2 y POR CONSOLA
 REQUISITOS MINIMOS DE MAQUINAS
REQUISITOS MINIMOS DE MAQUINAS
on las características mínimas que debe tener un hardware para soportar un software.